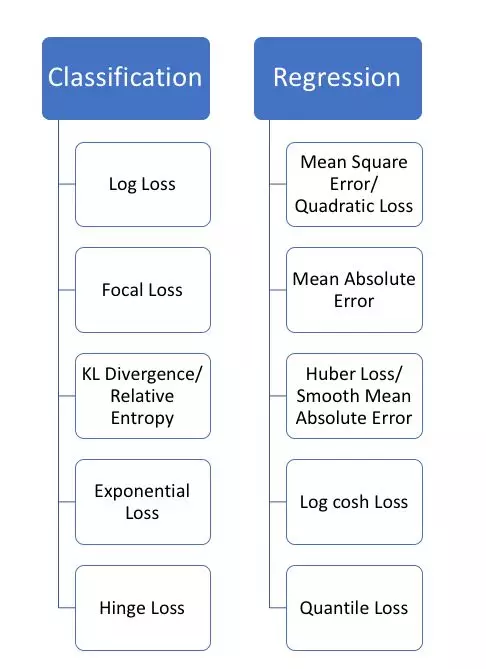
机器学习损失函数
损失函数
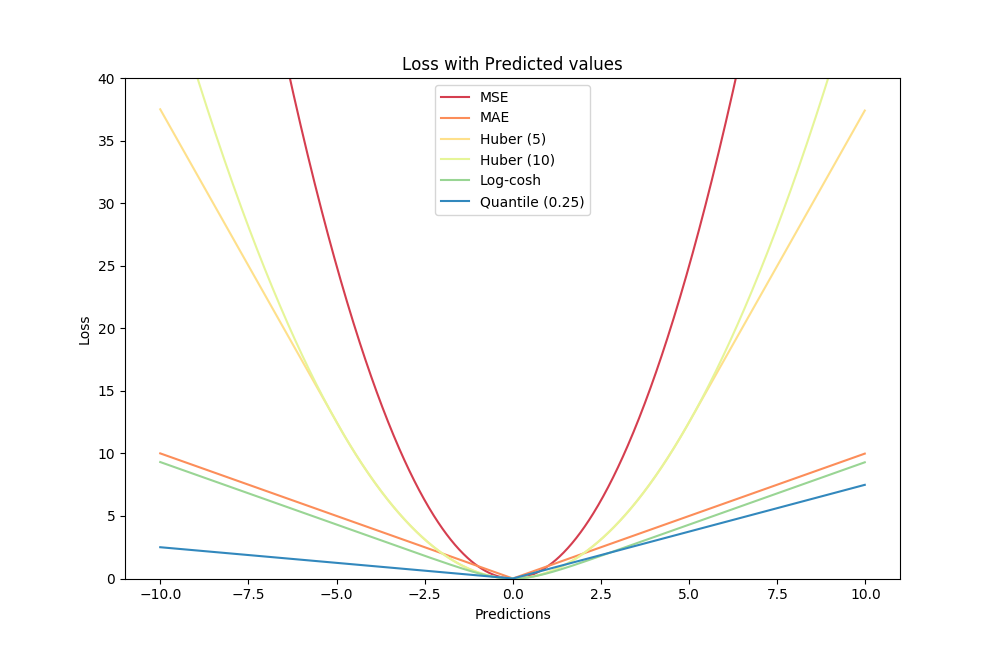
损失函数大致可分为两类:分类问题的损失函数和回归问题的损失函数。本文着重介绍回归损失。
Regression loss
- MSE
- MAE
- Huber loss
- Los cosh loss
- Quantile loss
Mean Square Error (MSE/ L2 Loss)
均方误差(MSE)是最常用的回归损失函数,计算方法是求预测值与真实值之间距离的平方和,公式如图。
下图是MSE函数的图像,其中目标值是100,预测值的范围从-10000到10000,Y轴代表的MSE取值范围是从0到正无穷,并且在预测值为100处达到最小。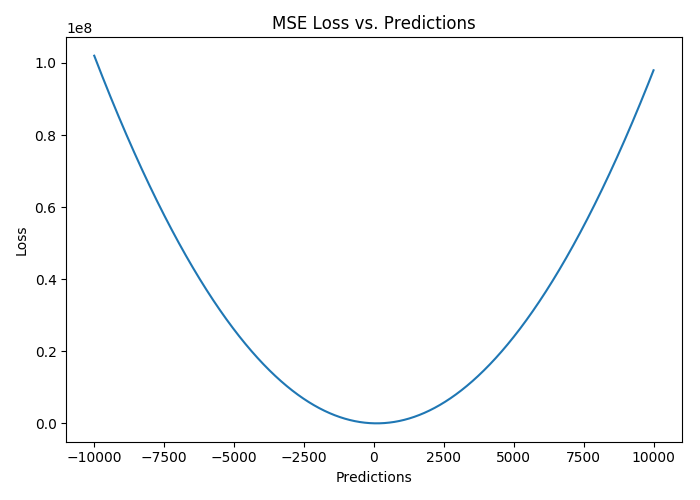
Mean Absolute Error (MAE/ L1 loss)
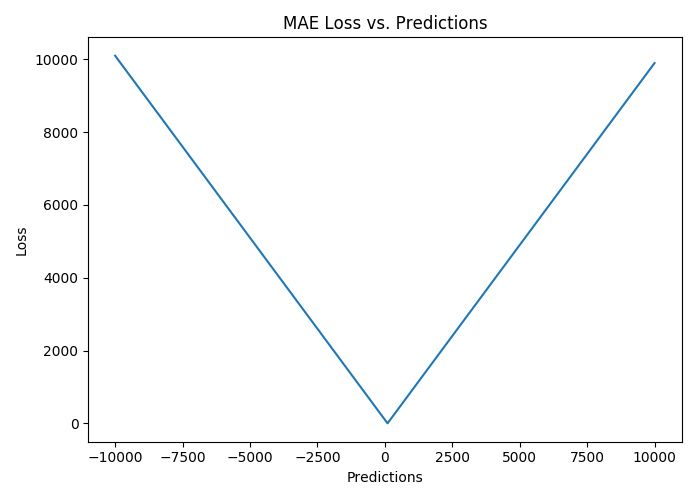
平均绝对误差(MAE)是另一种用于回归模型的损失函数。MAE是目标值和预测值之差的绝对值之和。其只衡量了预测值误差的平均模长,而不考虑方向,取值范围也是从0到正无穷(如果考虑方向,则是残差/误差的总和——平均偏差(MBE))。
简单来说,MSE计算简便,但MAE对异常点有更好的鲁棒性。下面就来介绍导致二者差异的原因。
训练一个机器学习模型时,我们的目标就是找到损失函数达到极小值的点。当预测值等于真实值时,这两种函数都能达到最小。
MSE(L2损失)与MAE(L1损失)的比较
简单来说,MSE计算简便,但MAE对异常点有更好的鲁棒性。
总而言之,处理异常点时,L1损失函数更稳定,但它的导数不连续,因此求解效率较低。L2损失函数对异常点更敏感,但通过令其导数为0,可以得到更稳定的封闭解。
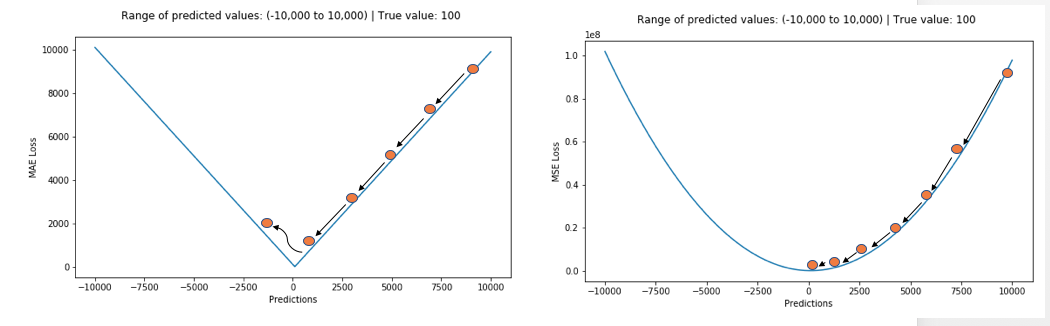 二者兼有的问题是:在某些情况下,上述两种损失函数都不能满足需求。例如,若数据中90%的样本对应的目标值为150,剩下10%在0到30之间。那么使用MAE作为损失函数的模型可能会忽视10%的异常点,而对所有样本的预测值都为150。
二者兼有的问题是:在某些情况下,上述两种损失函数都不能满足需求。例如,若数据中90%的样本对应的目标值为150,剩下10%在0到30之间。那么使用MAE作为损失函数的模型可能会忽视10%的异常点,而对所有样本的预测值都为150。
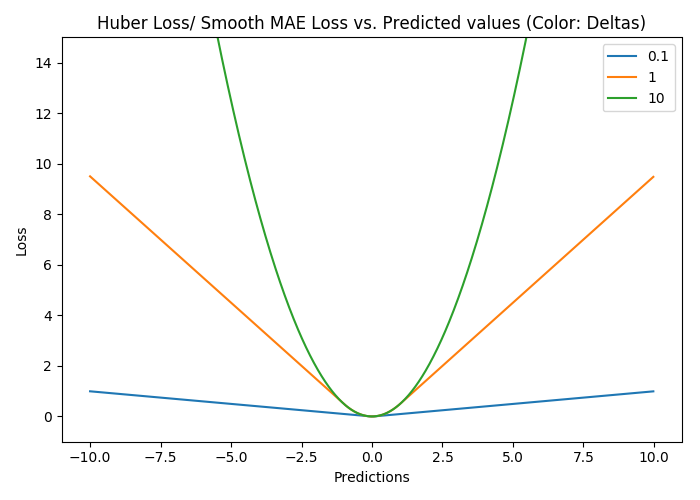
Smooth Mean Absolute Error/ Huber Loss
使用MAE训练神经网络最大的一个问题就是不变的大梯度,这可能导致在使用梯度下降快要结束时,错过了最小点。而对于MSE,梯度会随着损失的减小而减小,使结果更加精确。
在这种情况下,Huber损失就非常有用。它会由于梯度的减小而落在最小值附近。比起MSE,它对异常点更加鲁棒。因此,Huber损失结合了MSE和MAE的优点。但是,Huber损失的问题是我们可能需要不断调整超参数delta。
Log-Cosh损失
Log-cosh是另一种应用于回归问题中的,且比L2更平滑的的损失函数。它的计算方式是预测误差的双曲余弦的对数。
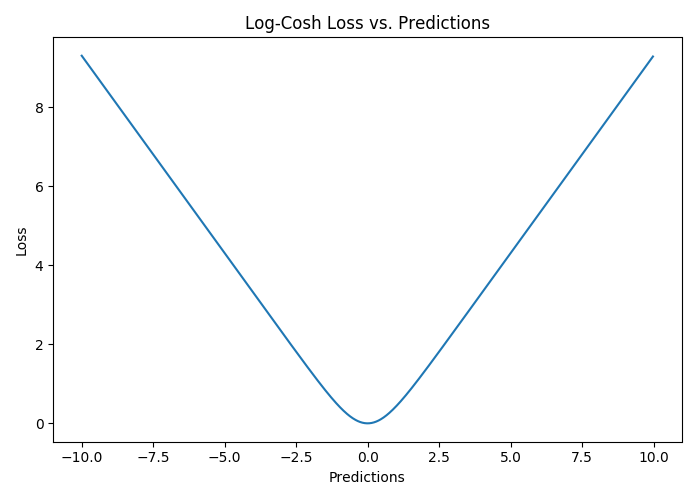 优点:对于较小的x,log(cosh(x))近似等于$(x^2)/2$,对于较大的x,近似等于abs(x)-log(2)。这意味着‘logcosh’基本类似于均方误差,但不易受到异常点的影响。它具有Huber损失所有的优点,但不同于Huber损失的是,Log-cosh二阶处处可微。
优点:对于较小的x,log(cosh(x))近似等于$(x^2)/2$,对于较大的x,近似等于abs(x)-log(2)。这意味着‘logcosh’基本类似于均方误差,但不易受到异常点的影响。它具有Huber损失所有的优点,但不同于Huber损失的是,Log-cosh二阶处处可微。
为什么需要二阶导数?许多机器学习模型如XGBoost,就是采用牛顿法来寻找最优点。而牛顿法就需要求解二阶导数(Hessian)。因此对于诸如XGBoost这类机器学习框架,损失函数的二阶可微是很有必要的。

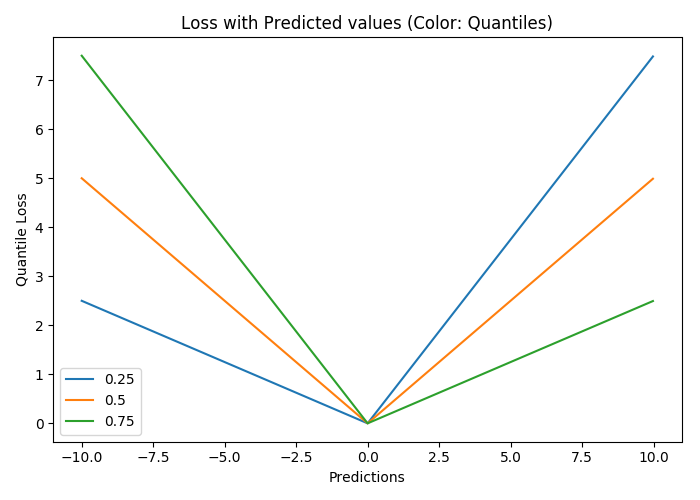
分位数损失
对比研究
为了证明上述所有损失函数的特点,让我们来一起看一个对比研究。首先,我们建立了一个从sinc(x)函数中采样得到的数据集,并引入了两项人为噪声:高斯噪声分量ε〜N(0,σ2)和脉冲噪声分量ξ〜Bern(p)。
加入脉冲噪声是为了说明模型的鲁棒效果。以下是使用不同损失函数拟合GBM回归器的结果。
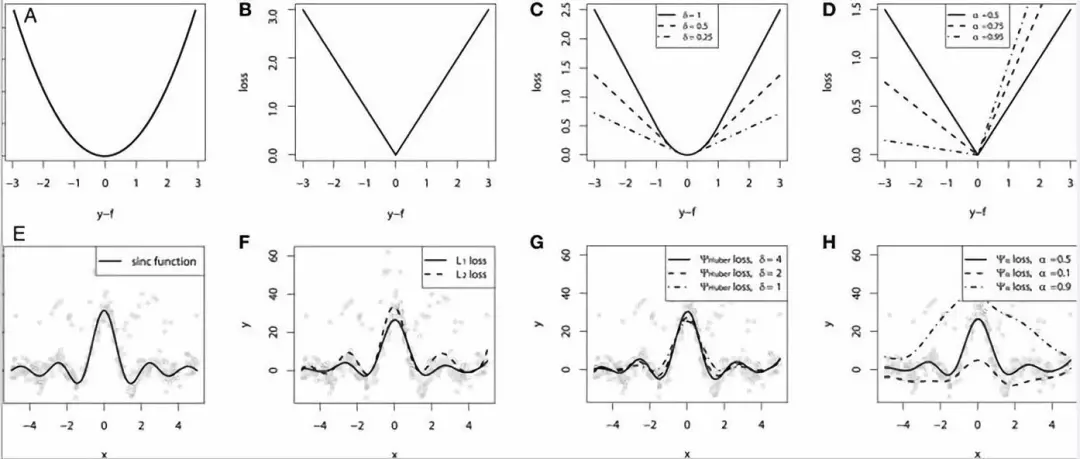 连续损失函数:(A)MSE损失函数;(B)MAE损失函数;(C)Huber损失函数;(D)分位数损失函数。将一个平滑的GBM拟合成有噪声的sinc(x)数据的示例:(E)原始sinc(x)函数;(F)具有MSE和MAE损失的平滑GBM;(G)具有Huber损失的平滑GBM,且δ={4,2,1};(H)具有分位数损失的平滑的GBM,且α={0.5,0.1,0.9}。
连续损失函数:(A)MSE损失函数;(B)MAE损失函数;(C)Huber损失函数;(D)分位数损失函数。将一个平滑的GBM拟合成有噪声的sinc(x)数据的示例:(E)原始sinc(x)函数;(F)具有MSE和MAE损失的平滑GBM;(G)具有Huber损失的平滑GBM,且δ={4,2,1};(H)具有分位数损失的平滑的GBM,且α={0.5,0.1,0.9}。
仿真对比的一些观察结果:
-
MAE损失模型的预测结果受脉冲噪声的影响较小,而MSE损失函数的预测结果受此影响略有偏移。
-
Huber损失模型预测结果对所选超参数不敏感。
-
分位数损失模型在合适的置信水平下能给出很好的估计。
参考:
https://heartbeat.fritz.ai/5-regression-loss-functions-all-machine-learners-should-know-4fb140e9d4b0
https://www.jiqizhixin.com/articles/2018-06-21-3

